Web’den Veri/İçerik Kazıma:Gazeteciler İçin Rehber
Çeviri: Bau İletişim Öğrencisi/ Dağ Medya Veri Gazeteciliği Stajyeri Faruk Aydıner
Yazı: http://gijn.org/2015/08/11/web-scraping-a-journalists-guide/ ‘den çevrilmiştir.
Bu yıl sadece birkaç saat önce Twitter’ın sekiz 8 milyar dolar kaybettiğini hatırlıyor musunuz? Bu veri habercileri gibi şirketlerin de kullandığı bir online araç web scraper yüzündendi.
Basitçe web scraper, web sitelerinden HTML kodlarını okuyan ve analiz eden bir bilgisayar programıdır. Böyle bir program veya ‘‘bot’’ ile websitelerinden bilgi ve veriyi çıkartmak mümkündür.
Haydi zamanda geriye gidelim. Geçen Nisan, Twitter üç aylık finansal sonuçlarını borsalar kapanırken açıklayacaktı çünkü sonuçlar biraz hayal kırıcıydı. Twitter borsacıların güvenini ölümcül bir şekilde kaybetmekten kaçınmak istiyordu. Talihsizce, bir hata yüzünden, sonuçlar 45 saniye boyunca borsalar hala açıkken çevrimiçi olarak açıklandı.
Sadece 45 saniye bir ‘‘bot’’ programının web scrape kullanarak sonuçları bulmasını, formatlamasını ve otomatikmen Twitter’ın kendisinde yayınlamasına izin verdi. (Bugünlerde, botlar bile zamandan zamana haberi ilk kez geçebilirler!)
#BREAKING: Twitter $TWTR Q1 Revenue misses estimates, $436M vs. $456.52M expected
— Selerity (@Selerity) 28 Nisan 2015
Bir kere tweet yayınlandığında, borsacılar çılgına döndü. Bu Twitter için bir felaketti. Botun sahibi olan şirket, anlık gerçek analizler de uzmanlaşan Selerity birçok eleştirinin hedefi oldu. Şirket durumu birkaç dakika sonra açıkladı.
Today’s $TWTR earnings release was sourced from Twitter’s Investor Relations website https://t.co/QD6138euja. No leak. No hack. — Selerity (@Selerity) 28 Nisan 2015
Bir bot için 45 saniye bir ebedi hayat gibidir. Şirkete göre, finansal sonuçları yayınlamak robot için sadece üç saniye aldı.
Web’de kazıyarak temizleme ve gazetecilik
Daha fazla kamu kuruluşu webte veri yayınladıkça, web scraping çevrimiçi gereci kodlama bilen gazeteciler için daha önemli hale geliyor. Örnek olarak, Metro gazetesinin bir haberi için, ben web scraping kullandım. Böylece Societe des alcohols du Quebec’den oniki bin ürün fiyatı ile LCBO’dan on bin ürünün fiyatlarını Ontario’da karşılaştırdım. Bir diğerinde, ben Sudbury’de iken restoranlardaki gıda denetimini araştırmaya karar verdim. Böyle bir araştırmanın bütün sonuçları Sudbury Health Unit’in websitesinde yayınlandı. Bununla birlikte, restorantları bir bir doğrulayarak bütün sonuçları indirme imkanı da var.
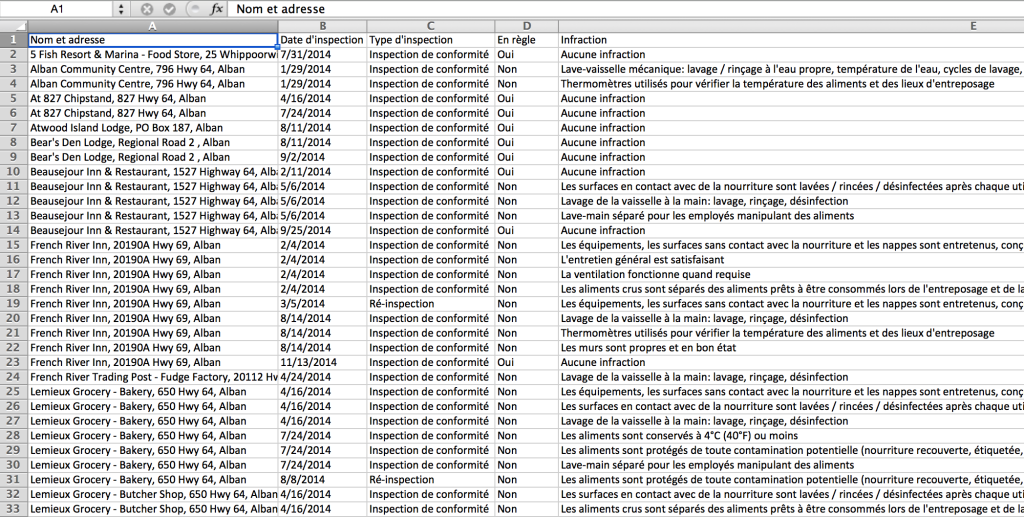
Bunu, sonuçların saklandığı kaynaktan bütün bir veri tabanı için istedim. İlk reddin ardından, bilgi edinme hakkından yararlandım, -sağlık ünitesi isteğimin işleme alınması için iki bin dolar ücreti istedikten sonra. Ödeme yerine, ben kendi botumu kodlamaya karar verdim bütün sonuçları direk olarak wesitesinden almak için. İşte sonuçlar:
Python kodlama ile benim programım the Selenium library ile Google Chrome’un kontrolünü ele alıyor. Bot Health Unit tarafından denetlenen 1600 hizmet kurumunun sonuçlarını tek tek tıklıyor, veriyi çıkartıyor ve bilgiyi bir Excel dosyasına yolluyor. Bunların hepsini tek başına yapmak birisi için haftalar alabilir. Benim botum için sadece bir gecelik işti.
Fakat benim botum yorulmadan binlerce satırlık kodu aktarırken, bir düşünce beni rahatsız etti: Web kazımanın etik kuralları nelerdir?
Webte bulduğumuz herhangi bir bilgiyi aktarmaya hakkımız var mı? Veri kazıma ve Hackleme arasındaki sınır nerededir? Nasıl sürecin şeffaf olduğundan emin olabilirsiniz? Hem hikayeyi okuyan halk, hemde hedef kurumlar için? Gazeteciler olarak, biz en yüksek etik standartlarıyla hareket etmeliyiz. Öteki durumlarda okuyucu onlara sunduğumuz olaylara nasıl inansın?
Ne yazık ki, kodlama yönetimi Federation professionnelle des journalists du Quebec, 1996’da benimsemiş ve 2010’da düzeltmiş olduğu içerik eskimekte ve sorularımın hiçbirine açık bir cevap verememekteydi. Kanadalı Gazetecilerin Organizasonunun etik klavuzu daha güncel olmasına rağmen yine de durumu aydınlatamamakta
Böylece, cevapları kendi kendime bulmaya karar verdim, bu ülkede yaşayan birçok gazeteciyle iletişime geçerek. Bizi okumaya devam edin; bu araştırmanın sonuçları devam eden bir bölümde açıklanacak.
Note: Eğer siz kendi kendinize web scrape kulanmak isterseniz, ben bir kısa ders serisi geçen Şubat’ta yayınladım. Siz Kanada Meclisi Websitesi’nden nasıl veri çıkarırsınız onu öğreneceksiniz!
Nael Shiab University of King’s College dijital gazetecilik bölümünden mezun oldu. O Kanada Radyosu video sunucusu olarak çalıştı. Şimdi ise veri gazetecisi olarak Transcontinental
Geri bildirim: Veri Gazeteciliği ve Web Kazımanın Etiği Üzerine